ARIES Example
Establishing a connection between an ARIES database and whitson+ through our external API is a standard practice. While this example involves an ARIES database, the majority of the steps are applicable to connecting any data source to whitson+, such as an SQL database.
Auto Update Prod Data to whitson+: Workflow Overview
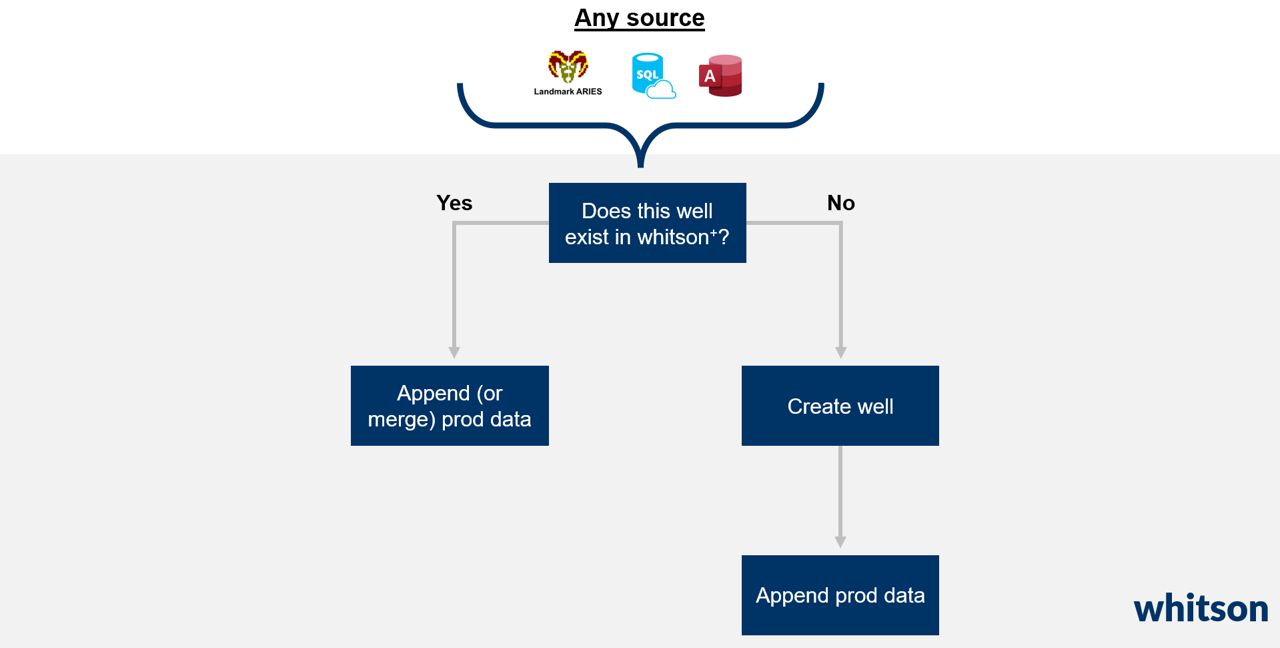
Engineers spend 95% of their time uploading data. This example demonstrates an automated daily update of production data. The process adheres to a widely used structure: connecting to a database, verifying if the well is already uploaded to whitson+, and creating a new well with production data if it isn't. Alternatively, if the well exists, it appends the new production data to the existing entity. Let's explore the details!
Connect ARIES to whitson+: Python Example
What does the aries.py file do?
This file shows an example of how one connect to an ARIES database and a relevant whitson+ domain. The file uses a helper class WhitsonConnection in whitson_connect.py provided here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | |
Windows Task Scheduler: Automating Daily Script Execution
A scheduler, such as the Windows Task Scheduler, is a tool vital for automating dataflow in and out of whitson+software upkeep. It enables the regular update of e.g. production data and the addition of new wells, ensuring the system stays current. The video above shows an example of how this done with Windows Task Scheduler.
Windows Task Scheduler
To run a Python script from the Windows Task Scheduler, follow these steps:
- Open Task Scheduler: Press Win + S, type "Task Scheduler," and hit Enter.
- Create a Basic Task: In the Actions pane, click on "Create Basic Task."
- Provide a Name and Description: Enter a name and description for your task, then click "Next."
- Choose Trigger: Select the trigger for your task. For example, choose "Daily" if you want to run the script every day. Click "Next."
- Set Trigger Details: Specify the start date, time, and recurrence pattern. Click "Next."
- Choose Action: Select "Start a Program" and click "Next."
- Specify Program/Script:
- In the "Program/script" field, provide the path to your Python executable (e.g., C:\Path\to\python.exe
- In the "Add arguments" field, provide the path to your Python script (e.g., C:\Path\to\your\script.py). Click "Next."
- Review Settings: Review your settings and click "Finish."
Now, your Python script will be executed automatically according to the schedule you specified. Ensure that the Python executable and your script paths are correct.
If you encounter any issues, you can check the Task Scheduler's "History" tab for information about the last run result. Additionally, make sure your Python script has the necessary permissions to access resources and that the Python interpreter is in the system's PATH or specify the full path to it.
Are there alternatives to Windows Task Scheduler?
Several alternatives to the Windows Task Scheduler exist, offering additional features and flexibility. Here are some popular alternatives:
Cron on Linux/Unix Cron is a time-based job scheduler in Unix-like operating systems. Users can schedule tasks using a cron syntax. It is particularly prevalent in Linux environments.
Task Scheduler on macOS Similar to the Windows Task Scheduler, macOS also has a built-in scheduler called launchd. It allows users to run tasks based on events or schedules.
Automate on macOS Automate is a built-in app on macOS that allows users to create scripts to automate tasks. It provides a graphical user interface for creating automation workflows.
cronie on Linux An extension of the cron daemon for Linux systems, providing additional features and compatibility with the traditional cron syntax. GNU at for Unix-like Systems Allows for one-time execution of commands at a specified time. Useful for ad-hoc scheduling.
Systemd Timers on Linux Systemd is a system and service manager for Linux, and it includes a timer component for scheduling tasks.
Third-party Task Scheduler Software Various third-party tools offer advanced features for task scheduling on different platforms. Examples include Task Scheduler Pro, VisualCron, and Advanced Task Scheduler.
Azure Logic Apps or Azure Functions In cloud environments like Azure, services like Logic Apps or Functions can be used for serverless task scheduling.
Choose the tool that best fits your requirements and integrates seamlessly with your workflow. The selection may depend on your operating system, specific scheduling needs, and the level of automation you seek.
Adding Logging to Python Script Run via Windows Task Scheduler
I found it somewhat hard to debug while using the Windows Task Scheduler, so found it very beneficial to use Python's logging library in tandem during the testing period.
Logging progress from a Python script running in the Windows Task Scheduler can be achieved by utilizing Python's logging module. Here's a basic example of how you can incorporate logging into your script:
1. Import the logging Module:
Add the following import statement at the beginning of your Python script:
1 | |
2. Configure the Logging:
Configure the logging settings. You can do this in your script's if name == "main": block or at the beginning of your script. For example:
1 2 | |
3. Log Progress:
Use the logging functions to log progress at various points in your script. For example:
1 2 3 4 5 6 7 8 9 10 | |
You can use different logging levels (DEBUG, INFO, WARNING, ERROR, CRITICAL) based on the importance of the logged information.
4. Review the Log File:
After your script runs through the Task Scheduler, you can check the log file (script_log.txt in this example) for progress updates and any logged information.
Remember to adjust the logging configuration and levels based on your needs. You can customize the log file path, logging format, and other settings according to your preferences.
This logging approach provides a convenient way to capture progress and debug information during script execution, making it easier to diagnose any issues that may occur when the script is run through the Windows Task Scheduler.