Bottomhole Pressure Example
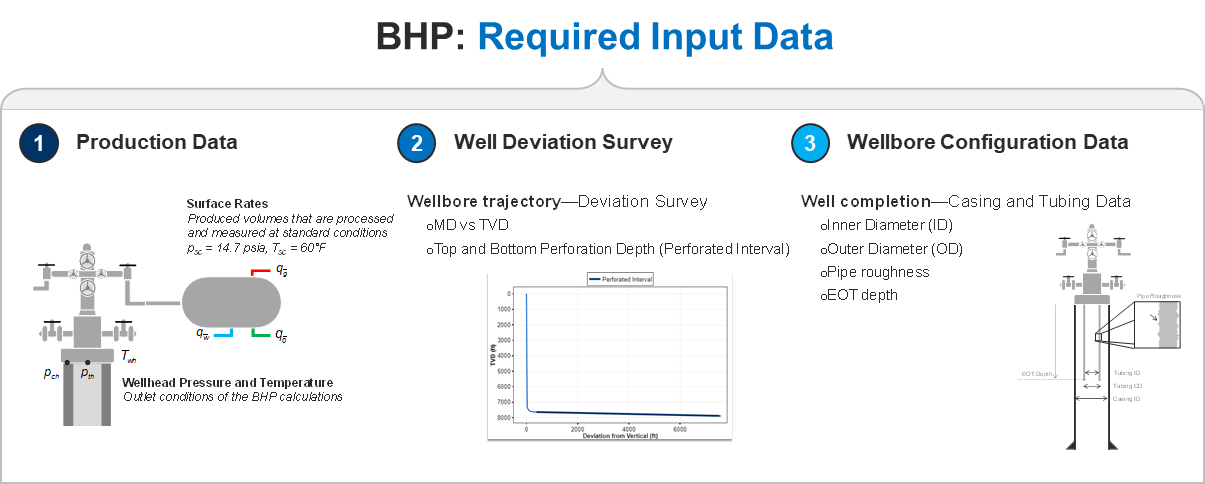
In this guide, our main focus is on leveraging the whitson+ API for uploading bottomhole pressure related data. The example can be broken down in four steps.
-
Uploading Wells and Wellheader Data, e.g. wellnames, UWI, etc.
-
Uploading Wellbore Data:, e.g. well deviation surveys, top/bottom perforations and
-
Uploading Production Data:, e.g. oil, gas and water rates.
-
Running BHP Calculations:, e.g. to be used in FMB, RTA, nodal or numerical modeling.
BHP Input Data Schema Visualization

This data schema shows how the different data tables are related.
Difference between WELL_ID and WELL_DATA_ID
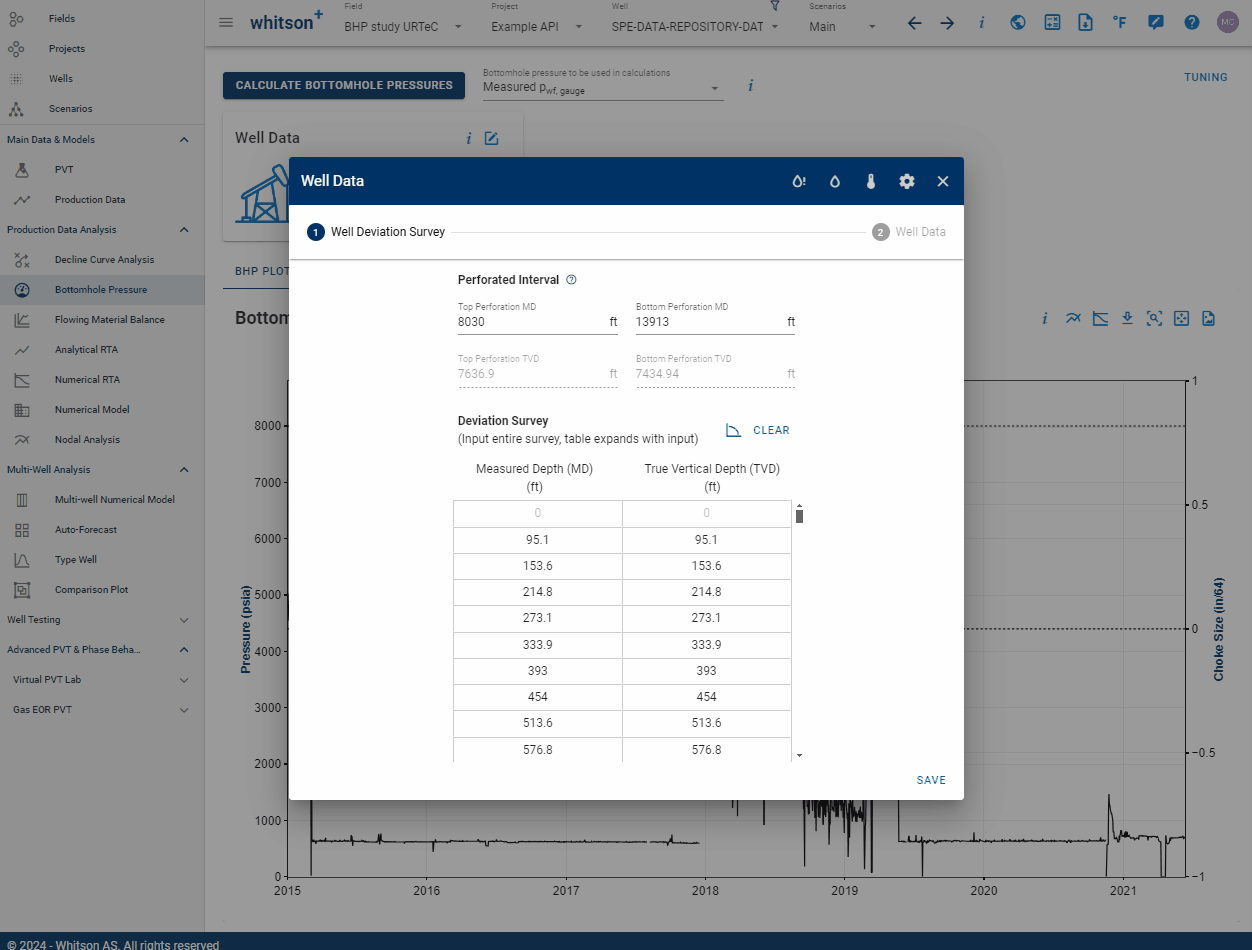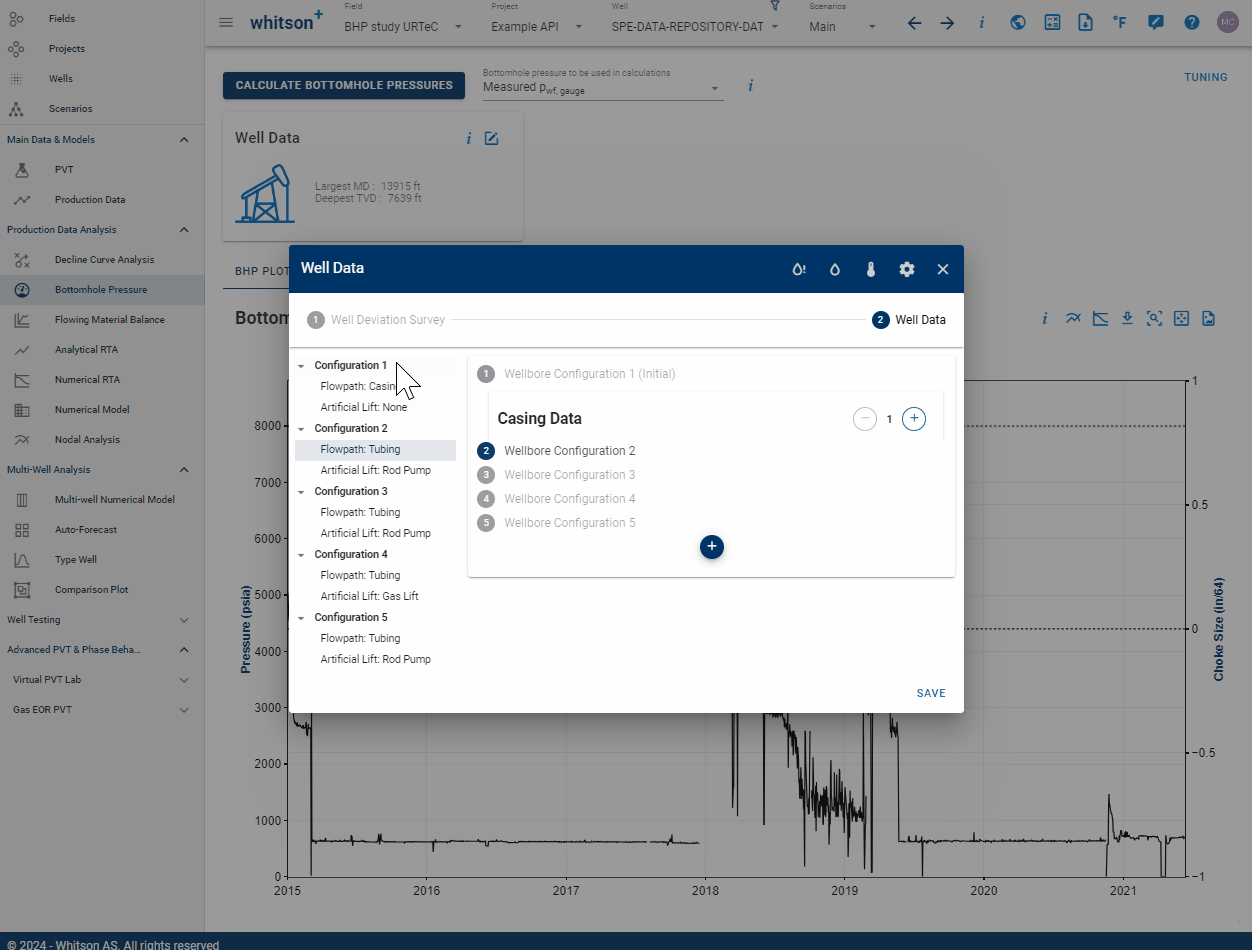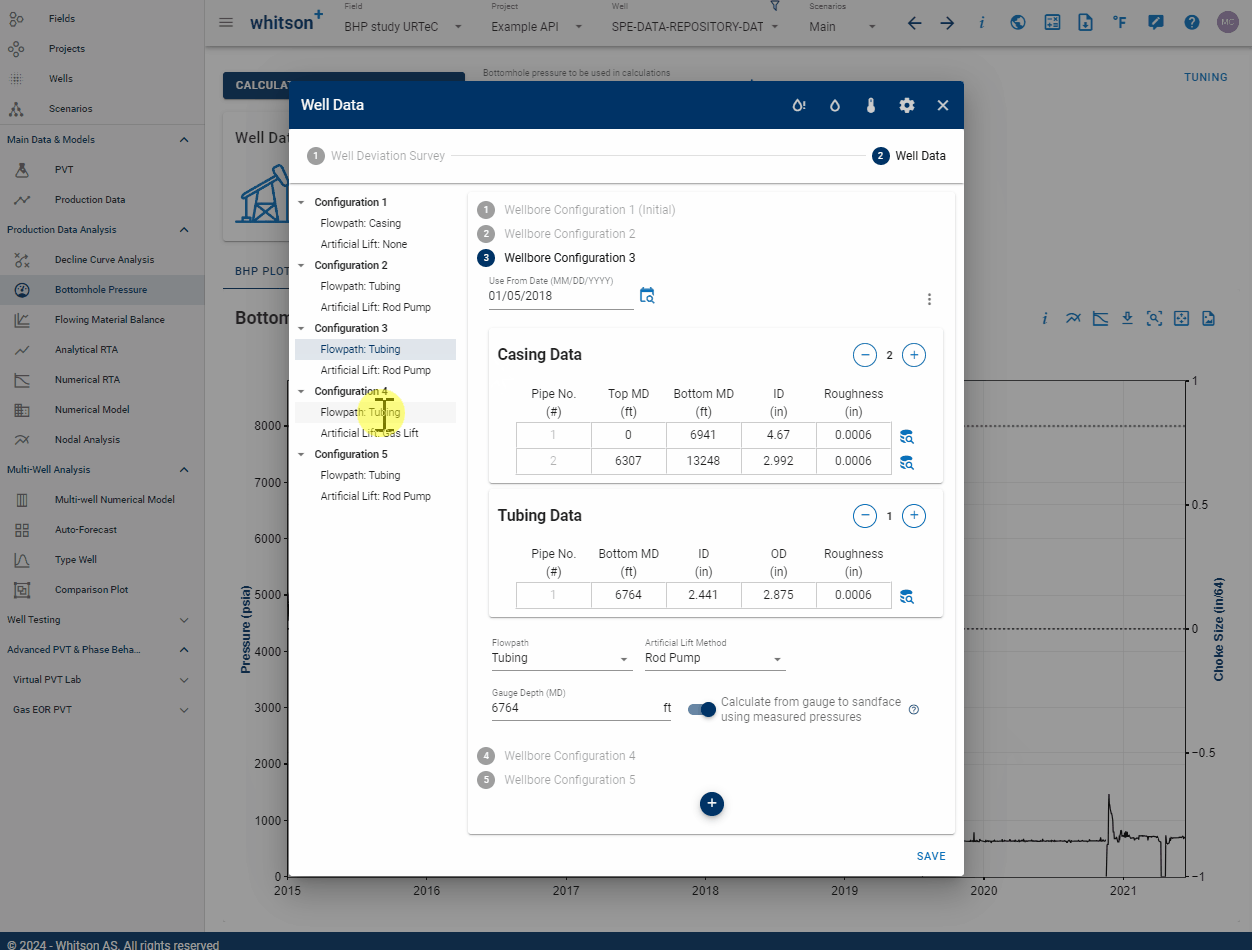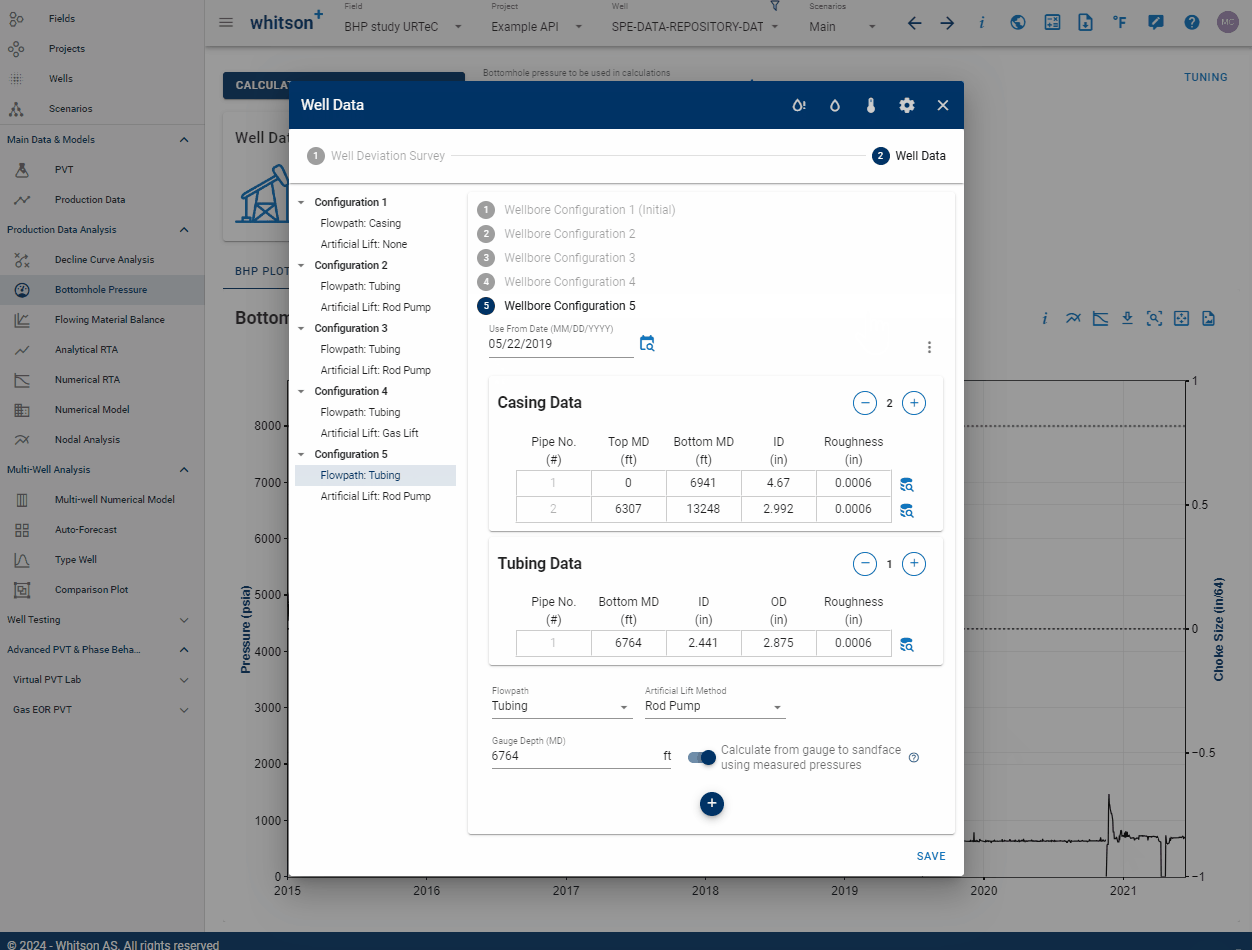
WELL_ID and WELL_DATA_ID serve different purposes. WELL_ID uniquely identifies a specific well, while WELL_DATA_ID is assigned to each wellbore configuration. Over time, multiple configurations can occur. For instance, initially flowing through casing and later installing tubing would result in two separate wellbore configurations, each with its own WELL_DATA_ID and installation DATE
Connect BHP data to whitson+: Python Example
What does the bhp.py file do?
This file shows an example of how one connect BHP data to the whitson+ domain. The file uses a helper class WhitsonConnection in whitson_connect.py provided here. The example data is from a standard whitson+ MASS UPLOAD example that can be downloaded here. Modifying the code to e.g. pulling data from a SQL table is straight forward, as exemplified below.
Connect BHP data to whitson+: Python Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 | |
Reading Data from a SQL Table
The example above demonstrates how to read data from an excel template into whitson+. The code can be easily modified to read from a SQL database into whitson+ instead. Example of how to read SQL into a Pandas Dataframe can be seen below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
WellView Queries: Relevant Tables and Queries

Below are example SQL queries designed to extract specific information from the a WellView database. These queries demonstrate how to retrieve tubing components, survey data, perforation details, and casing specifications for wells in select counties. Each query includes placeholders for conditions and patterns to be adjusted according to specific requirements. Note that these examples reference relevant WellView tables and are provided for illustrative purposes only.
Example: Deviation Survey Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Example: Perforation Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Example: Casing Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Example: Tubing Component Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Example: Wellbore Configuration Query
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 | |