Reservoir Simulation - Probabilistics
This module enables users to perform probabilistic analysis on one or more variables at once.
As shown in the GIF below, the probabilistic feature can be used to generate probabilistic simulation results for chosen variables by repeated sampling of the distributions selected for these variables and rerunning the Numerical Model - as many times as the chosen number of cases. The results generated will first be sorted by error to exclude the cases above the error threshold, and only the qualified cases are ordered for the computation of the P90, P50, P10 and the flowing confidence interval (shaded areas) in the displayed plots and summary results table.
At least one variable is required to perform this analysis. The number of cases can be changed with a minimum of 1 and a maximum of 1000 cases.
There are four distribution types with different inputs required:
| Distribution Type | Required Inputs |
|---|---|
| Constant | Value |
| Uniform | Minimum and maximum value |
| Triangular | Minimum, peak, and maximum value |
| Normal | Minimum (P90), maximum (P10), mean value, and standard deviation |
| Log-Normal | Minimum (P90), maximum (P10), mean value, and standard deviation |
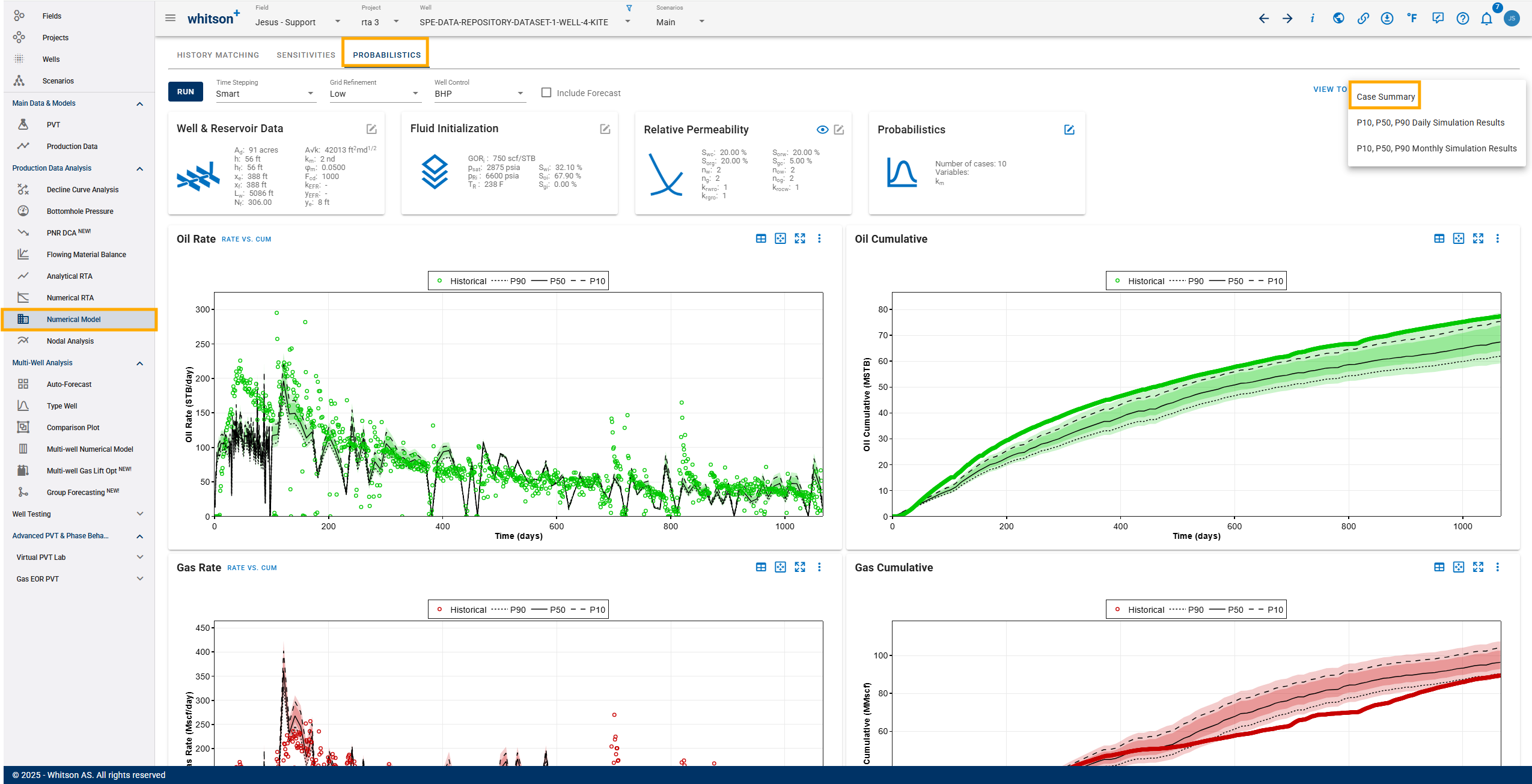
The "View Summary" button can be used to see the summary of P90, P50, P10, mean and standard deviation of the variables in numbers. You can also export the summary and/or the simulated results by clicking the "Export" button.
If you recall, the Numerical Model section has the following toggles -
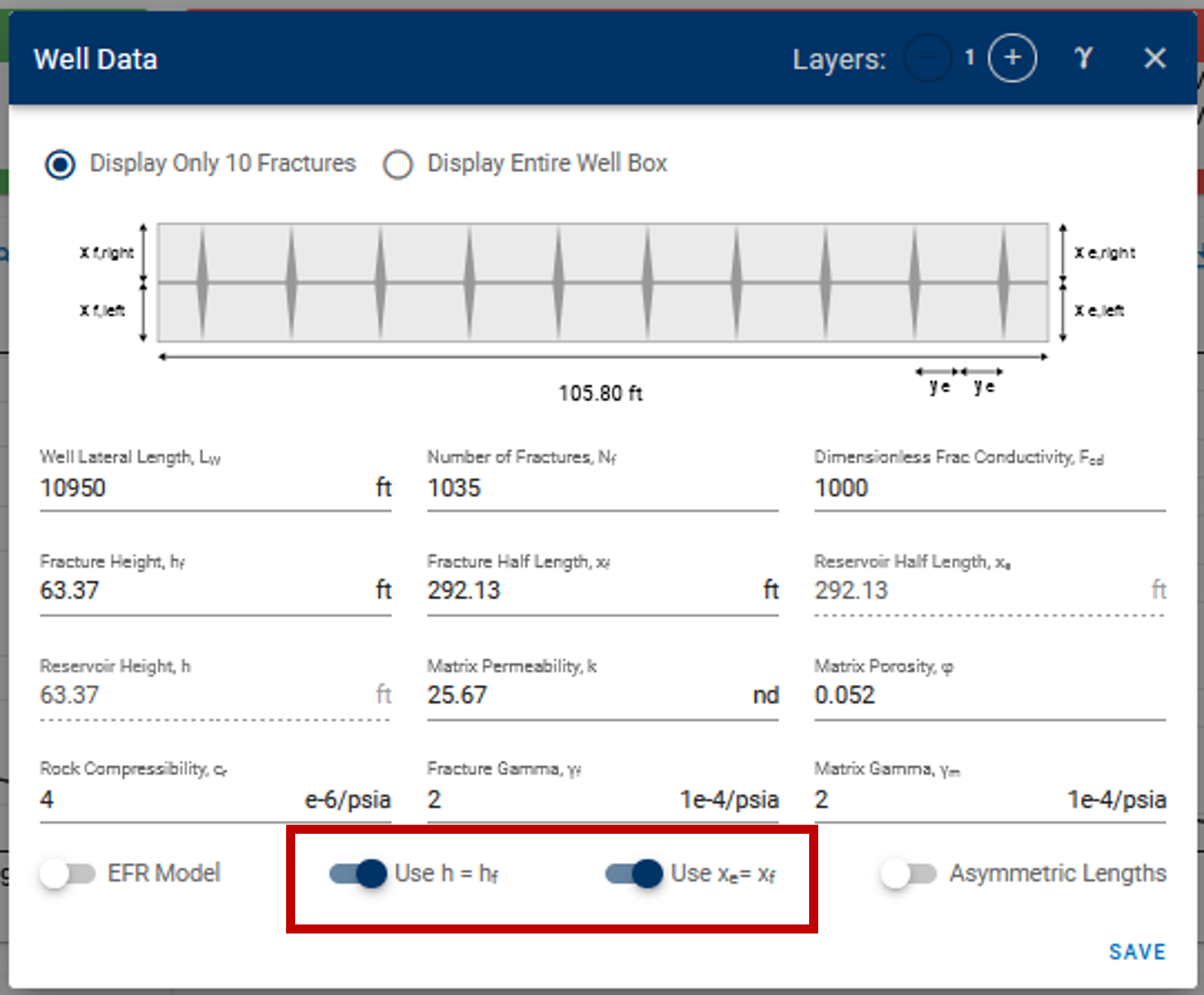
Toggles for h and xe in Numerical Model settings
Here, if the toggles are switched on, the reservoir height and reservoir half-length are always enforced to be equal to fracture height () and fracture half-length () in all simulations — this includes simulation calls via cases in sensitivities and probabilistics.
The default behavior in the probabilistics feature when running probabilistics with (Reservoir half-length) and (Fracture half-length):
- If you have in the model (toggle is on) — then any specified values are ignored for the given in probabilistics and is enforced to be equal to this in the probabilistics case. Base case is set as if is not provided.
- If you have (toggle is off) — then specified values of are used, and if they are blank, the base case is used.
Essentially, sensitivities and probabilistics cannot override these toggles. To freely adjust and , go to the History Matching section and turn off these toggles on the Numerical Model card and click save before running sensitivities.
Similar behavior when toggle is on/off for the other pair of variables — | .
Invalid cases
A sampled case is marked as invalid if or . Invalid cases are excluded from the valid case count and will not be included in the P90, P50, and P10 results. If you see invalid cases, tighten the parameter bounds so and .
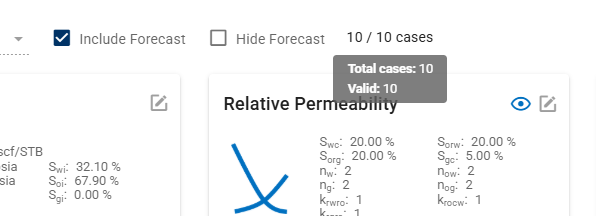
1. Definition of P10, P50, P90
First cases are ordered/ranked by cumulative production at end of history.
- Dry gas and wet gas are ranked by cumulative gas production at end of history.
- Black oils, volatile oils, near-critical fluids and gas condensates are ranked by cumulative oil production at end of history.
In the software we have chosen to define P10 case as the 10th percentile best-case scenario. In a similar manner, P90 is the 90th percentile best case and P50 is the median.
Why do we do it like this?
We want the P10 case of gas to match the P10 case of water (and oil when relevant).
If we assumed a normal distribution at every point and used the rates to calculate the standard deviation for every point to define the P10 case in for each plot, then the P10 stems of gas, water and oil would have no physical connection between them. This would not make sense.
However, a normal distribution on every point (or a flowing confidence interval) provides a lot of insight as well. The colored area is meant to visualize this:
- the middle of the dark area is the average,
- edges of the dark area are one standard deviation outside,
- edges of the light-colored area are two standard deviations outside.
What does this mean: if you run a new case with inputs inside the boundaries you have set, there is a ~95% probability that the simulation will exist within the entire colored area (roughly estimated as we do not account for covariances)
Summary: P10, P50 and P90 cases are the same physical simulations in every plot. Colored areas are the 1- and 2-sigmas confidence interval for a new simulation.
2. Error Calculation
3. Running Probabilistics - Targets, Objectives, Weights and Error Thresholds
In the Numerical Model - Probabilistics view, click on the Edit button on the probabilistics card. This opens a dialog box for probabilistic case settings and results are generated with three simple steps -
- Select Variables - Choose from a range of available variables to run probabilistic simulations.
- Set Limits - Choose the number of cases to run and set up a distribution (from the types above) for each chosen variable to sample values from.
- Weight Factors - Choose the main objective functions (matching oil rate, gas rate, water rate, BHP or all of them) to compute error against by enabling the weight factor for that stream. You can also add an error threshold here, where all cases resulting in errors above the error threshold will be excluded from the P90, P50 and P10 calculations.
Weight factors used in Numerical Model - History Matching
💡 Weight factors used in History Matching are carried over to the probabilistic feature to rank cases.
In History Matching, if you have manually increased the weights of certain/all parts of well pressure production history (default 1, high importance 10, no importance 0 - typically used for autofitting the Numerical Model parameters), the same is honored when calculating the total RMS error for each probabilistic case. If a stream is toggled off, the weight factors for that stream are all set to zero so it will not be used to calculate the total RMS error of the case.
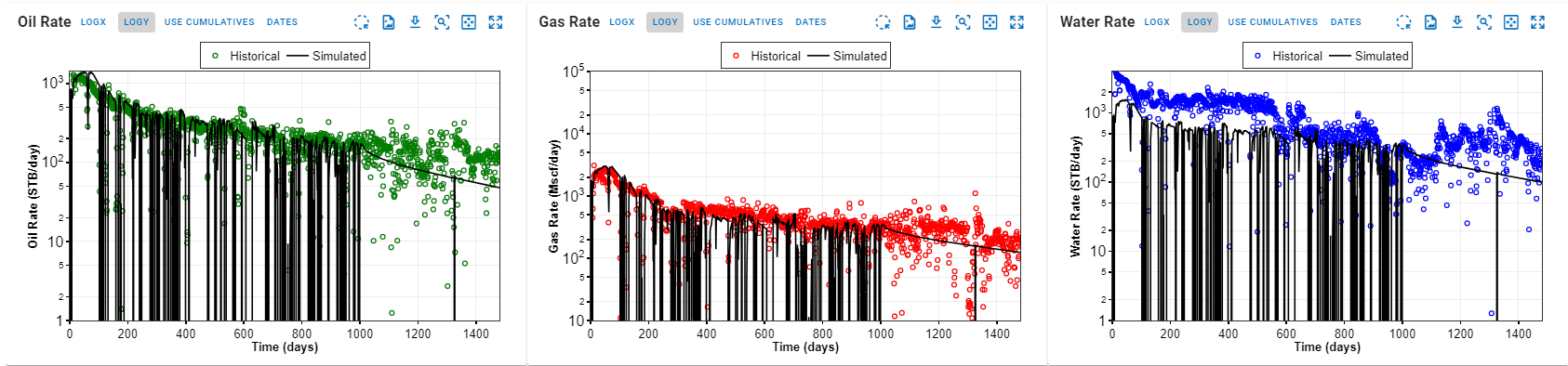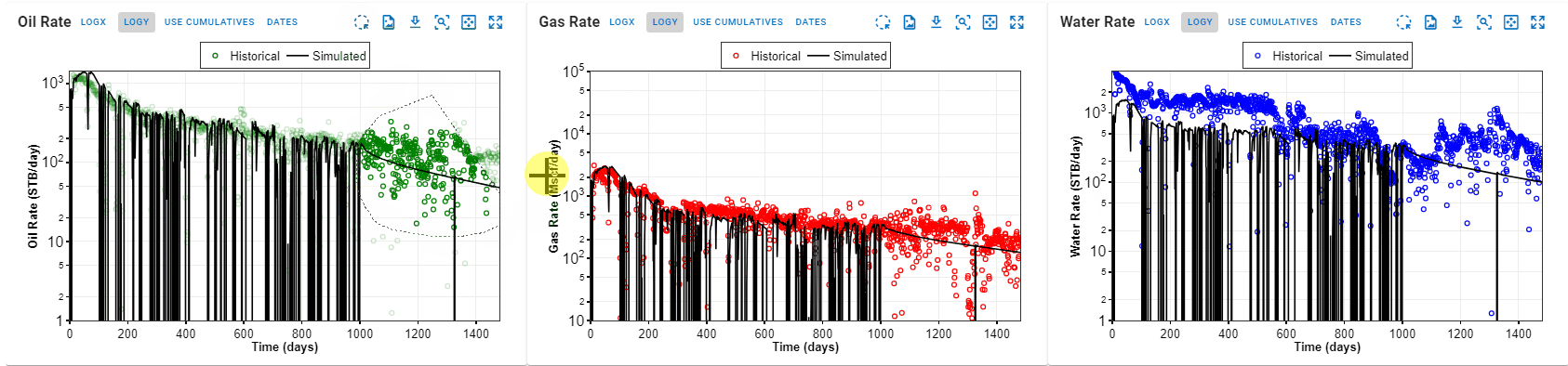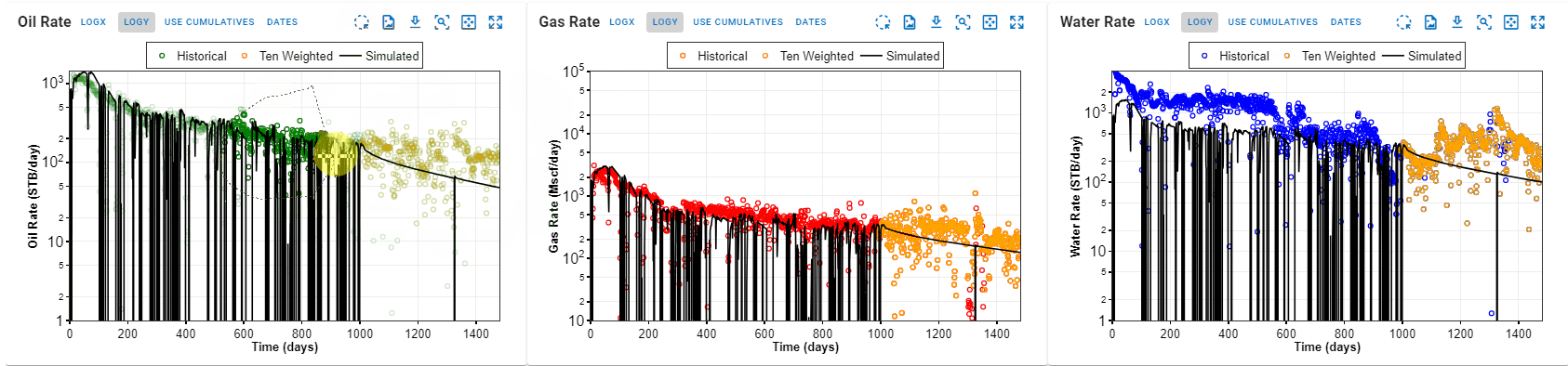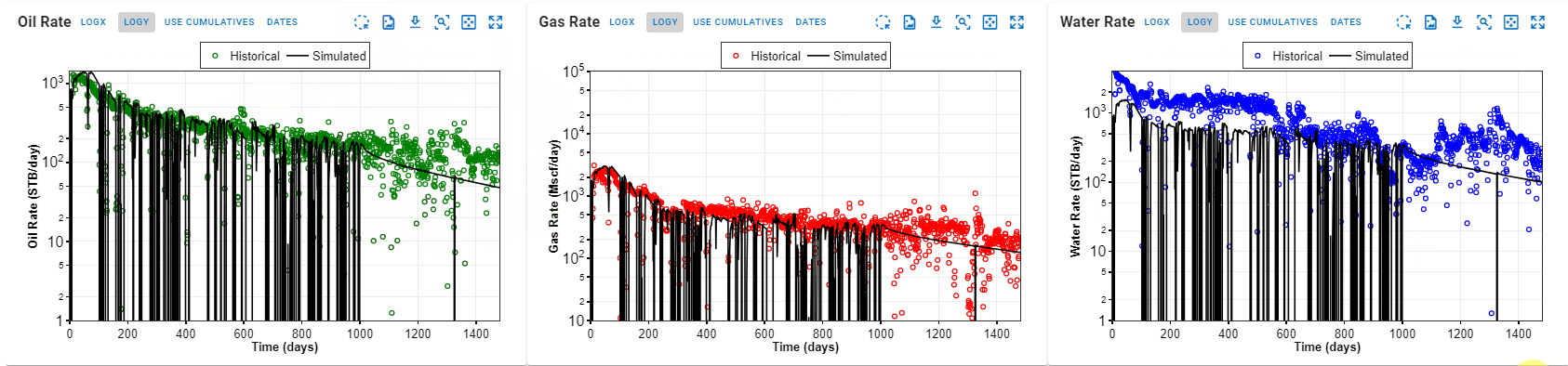
4. How to Handle Simulation of Different pRi and GORi?
The black-oil PVT table is always generated in whitsonʳˢ from initial composition (), reservoir temperature (), equation of state (EOS), and surface process configuration. The black-oil PVT table is always regenerated locally at runtime, taking only a fraction of a second. This approach ensures flexibility and avoids delays previously encountered when downloading pre-generated BOT files from the cloud.
Current handling for variations in initial reservoir pressure () and initial GOR ():
The black-oil PVT table is primarily a function of (through ) and (). The is used to initialize the fluid as either single-phase or two-phase. This parameter is not a direct input in the generation of the black-oil PVT table but is used during its extrapolation to avoid numerical instabilities of negative compressibility and internal extrapolation as much as possible. Therefore, the extrapolated part of the black-oil PVT table (affected by ) is typically outside the region used in simulations and should not materially impact the quality of the results.
-
Variations in with fixed
When is held constant, the same is used across all cases. Varying influences the initialization of the fluid system:
- If ≥ , the fluid initializes as single-phase.
- If ≤ , the fluid initializes as two-phase.
Effects of Varying with Fixed
If you compare the files of two History Matching cases with same , but different , there may also be some differences in the extrapolated part of the black-oil PVT table, but that should not impact the simulations.
-
Variations in with fixed
Changing the is equivalent to altering the . For each case, black-oil PVT table will be generated using different composition. A new composition () is generated by taking the original obtained from Fluid Definition and recombining it to match the specified . A new BOT is then constructed based on () and used in the simulation.
-
Variations in both and
Both effects described in previous points are applied simultaneously.
5. Forecast
Once the variables have been chosen and the model has been run, the results can be used to forecast production. By clicking the "Include Forecast" button, you can append the forecast to the data. However, any edits to the forecast schedule must be made in the History Matching section, and the simulation must be rerun after any changes or when toggling the forecast inclusion on or off.
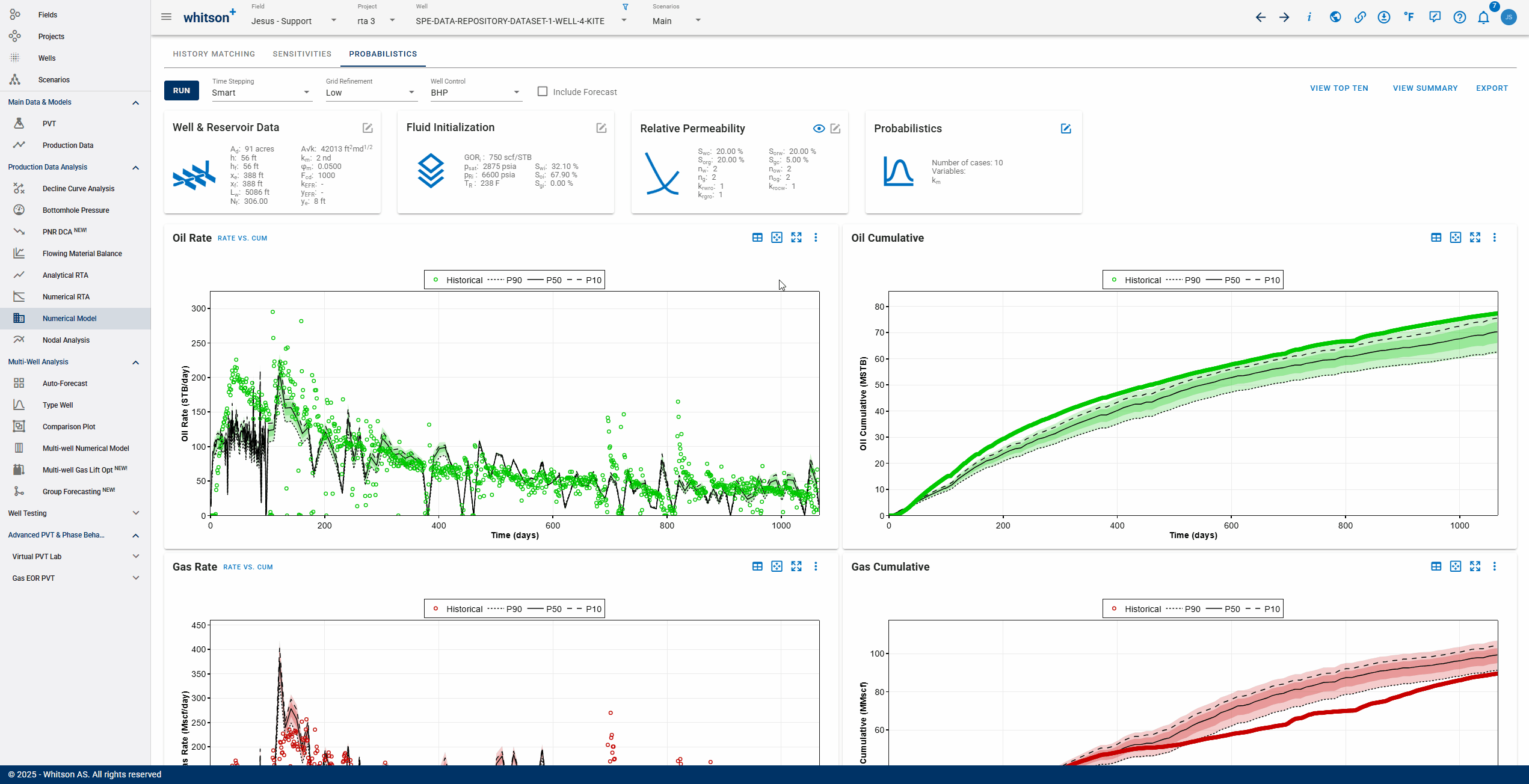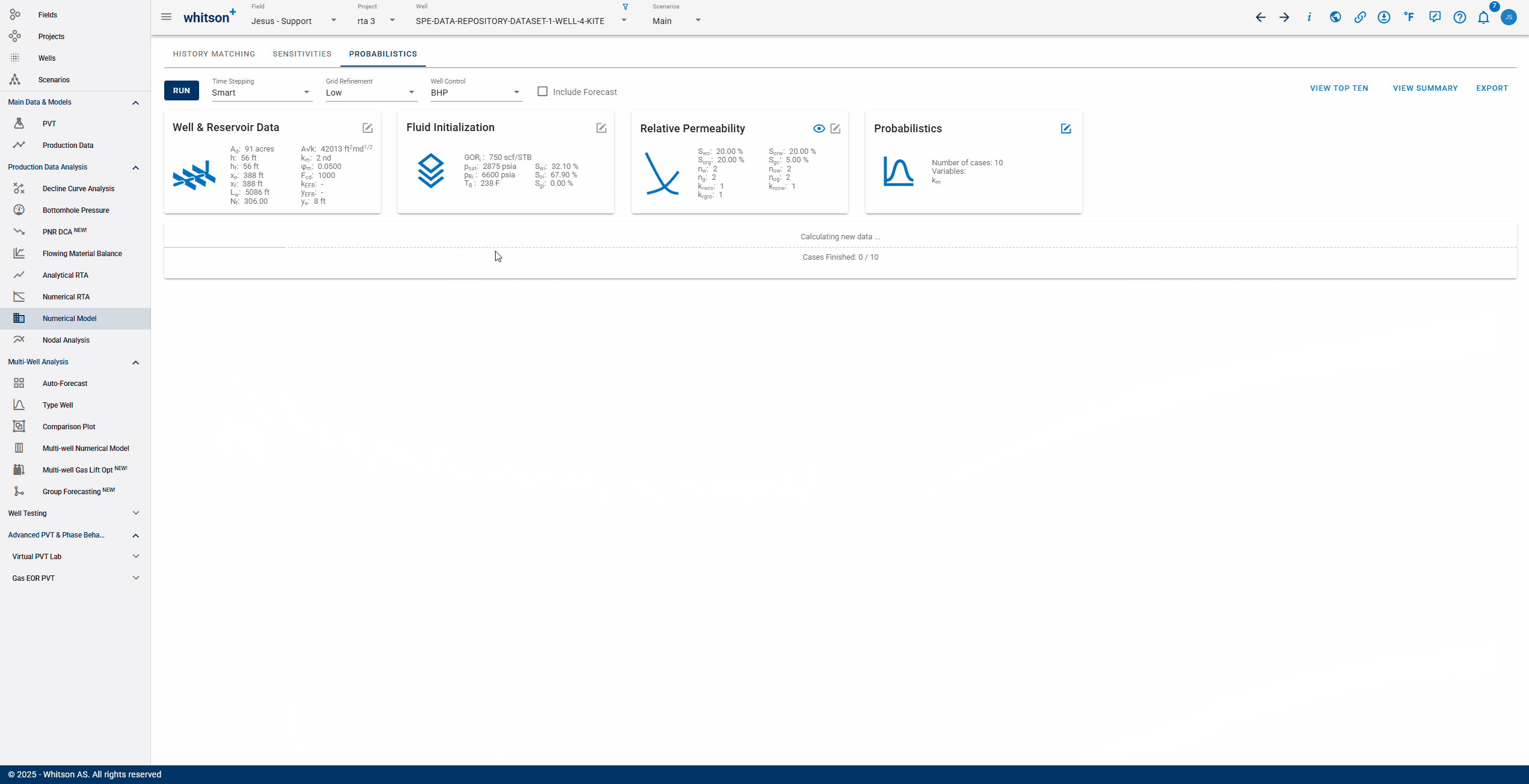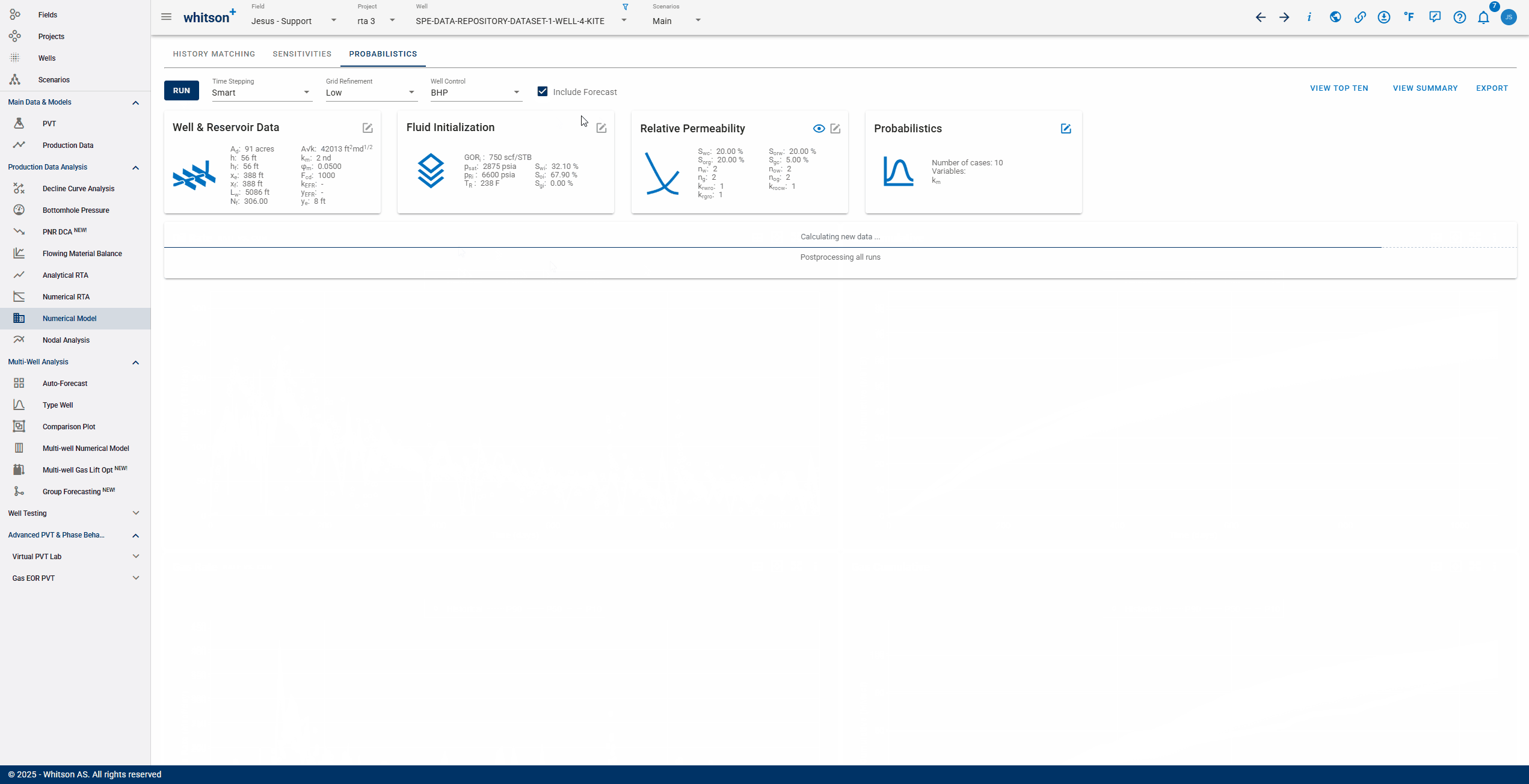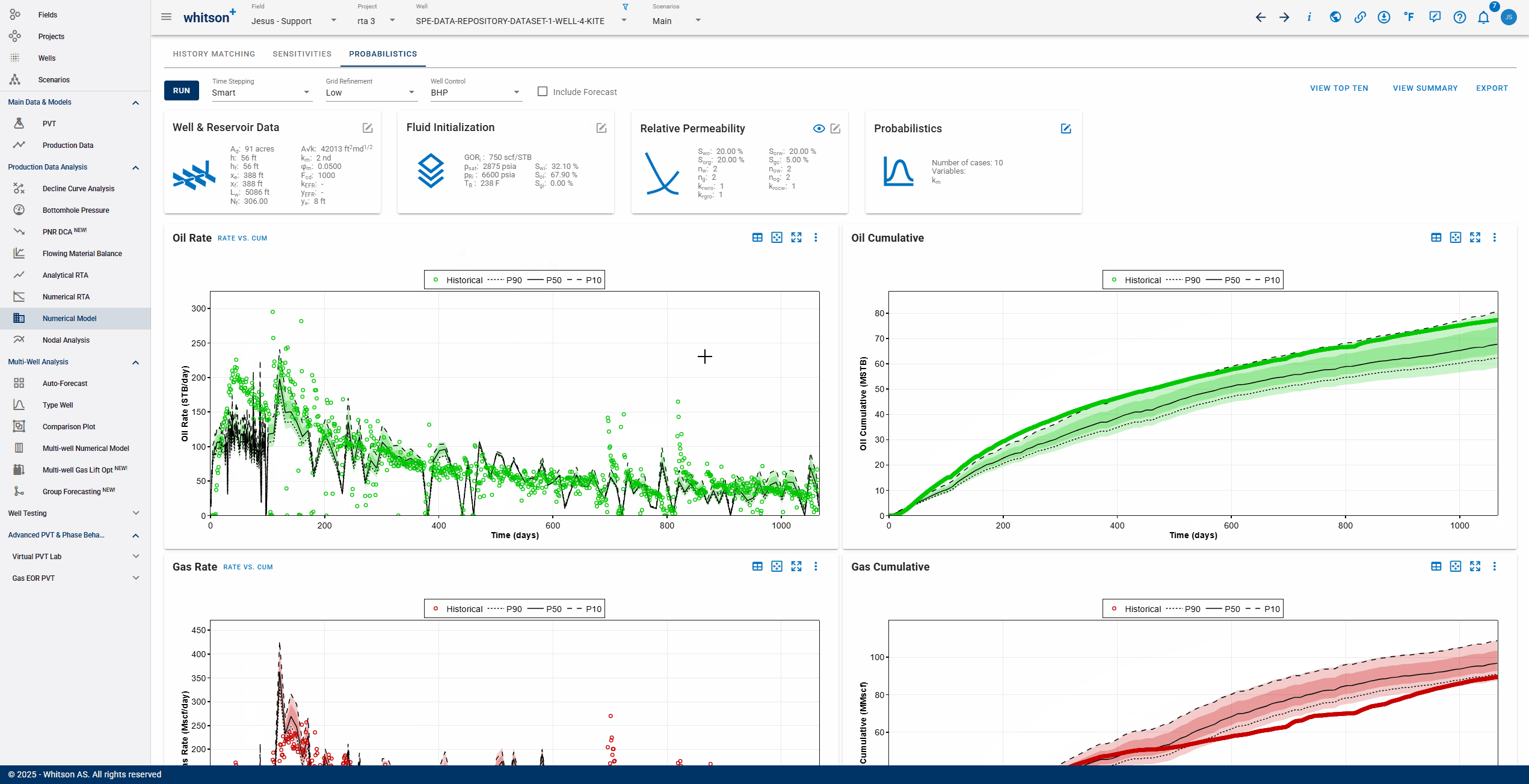
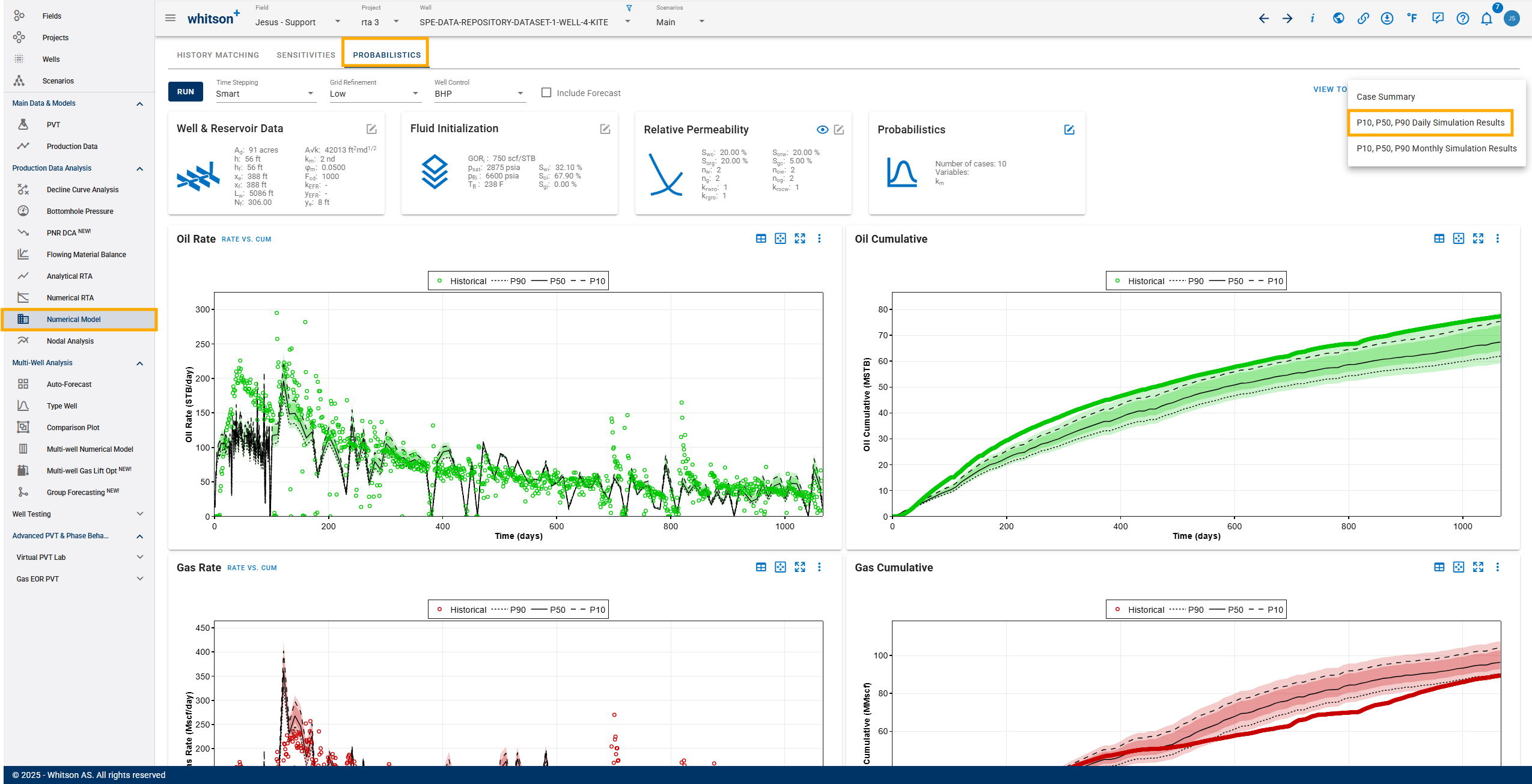
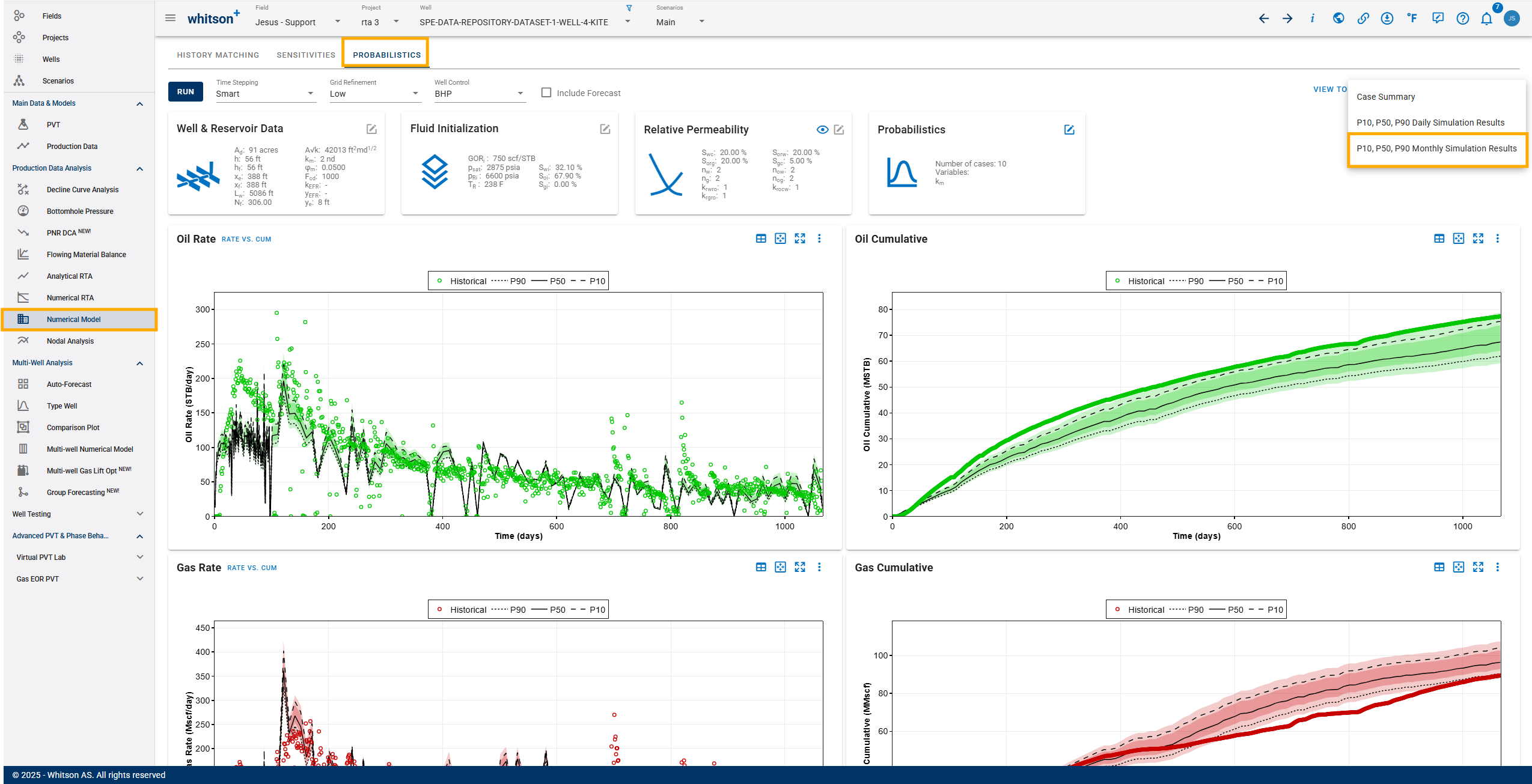
6. Export
To date, the probabilistic results can be exported in excel format in daily or monthly option. You can also export a case summary.